*CTF-REVER-WP
0x1 Simple File System
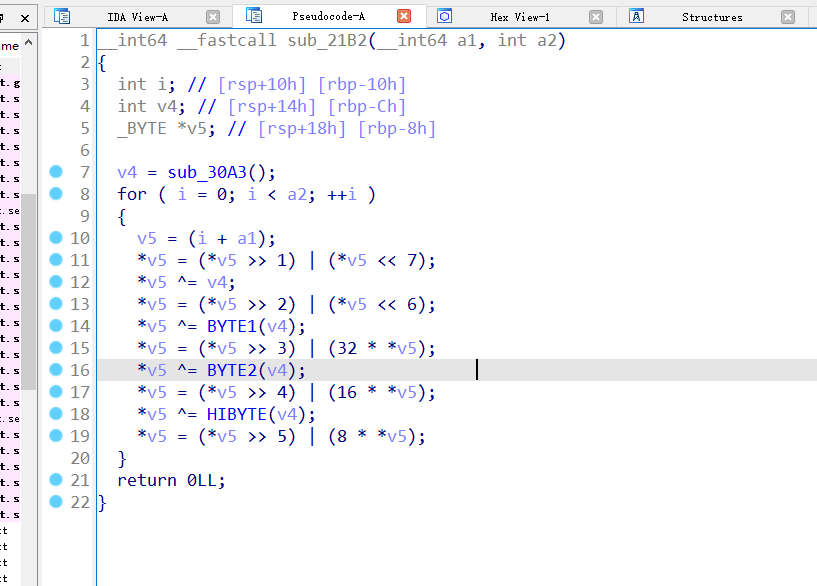
找到关键加密位置
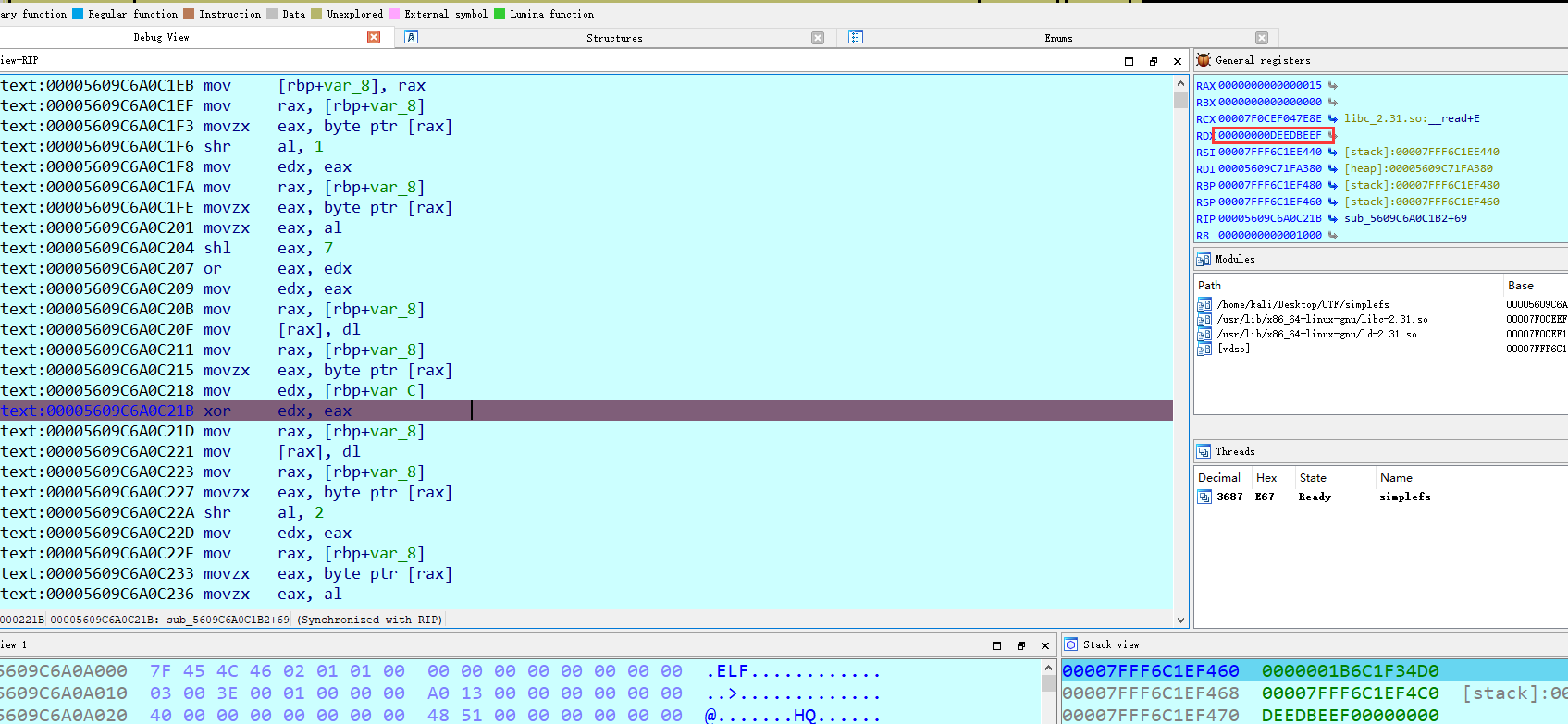
动调得到V4的值
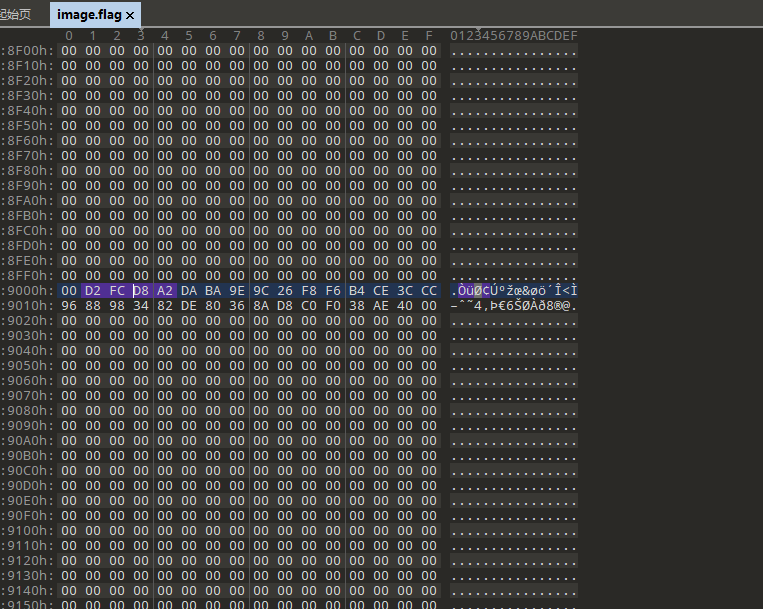
在image.flag找到密文。因为*ctf加密开头是不变的,所以通过特征码搜索。
data=[0x00, 0xD2, 0xFC, 0xD8, 0xA2, 0xDA, 0xBA, 0x9E, 0x9C, 0x26, 0xF8, 0xF6, 0xB4, 0xCE,
0x3C, 0xCC,0x96, 0x88, 0x98, 0x34, 0x82, 0xDE, 0x80, 0x36, 0x8A, 0xD8, 0xC0, 0xF0, 0x38, 0xAE,0x40, 0]
for i in range(len(data)):
for j in range(32,128):
x = j
x = (x >> 1) | (x << 7)&0xff
x ^= 0xef
x = (x >> 2) | (x << 6)&0xff
x ^= 0xbe
x = (x >> 3) | (32 * x)&0xff
x ^= 0xed
x = (x >> 4) | (16 * x)&0xff
x ^= 0xde
x = (x >> 5) | (8 * x)&0xff
if x ==data[i]:
print(chr(j),end="")
#*CTF{Gwed9VQpM4Lanf0kEj1oFJR6}*python爆破一下
0x2 NaCl
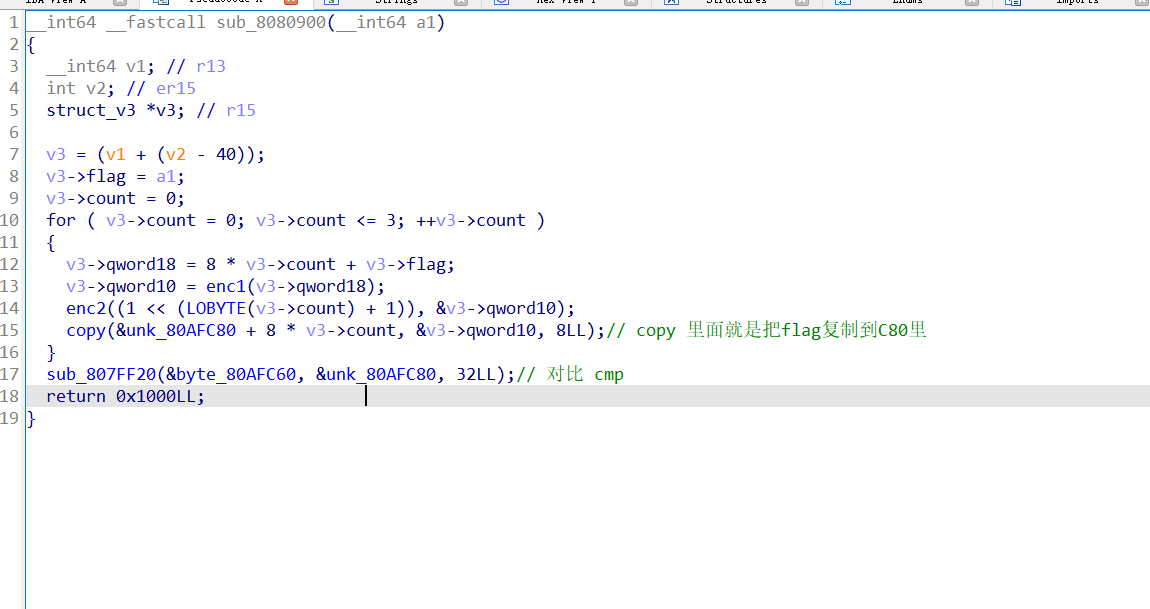
第一步先是用ida脚本修复逻辑
start = 0x807FEC0
end = 0x8080AD1
address = [0 for i in range(5)]
callTarget = ["lea", "lea", "mov", "jmp"]
retnTarget = ["lea", "mov", "and", "lea", "jmp"]
def nop(s, e):
while (s < e):
patch_byte(s, 0x90)
s += 1
def turnCall(s, e):
# nop掉call之前的值
nop(s, e)
patch_byte(e, 0xE8)
# 把后面的花指令去掉
huaStart = next_head(e) #next_head取下一条指令
huaEnd = next_head(huaStart)
nop(huaStart, huaEnd)
def turnRetn(s, e):
nop(s, e)
# 注意原来是jmp xxx
# 所以前面nop掉一个 后面改成retn
patch_byte(e, 0x90)
patch_byte(e + 1, 0xC3)
p = start
while p < end:
address[0] = p
address[1] = next_head(p)
address[2] = next_head(address[1])
address[3] = next_head(address[2])
address[4] = next_head(address[3])
for i in range(0, 4):
if print_insn_mnem(address[i]) != callTarget[i]: #print_insn_mnem 取指令
break
else:
turnCall(address[0], address[3])
p = next_head(next_head(address[3]))
continue
for i in range(0, 5):
if print_insn_mnem(address[i]) != retnTarget[i]:
break
else:
turnRetn(address[0], address[4])
p = next_head(next_head(address[4]))
continue
p = next_head(p)此脚本是pz师傅写的,可以观看视频有详细讲解原理,关注一下pz师傅。
https://www.bilibili.com/video/BV1D541127ug?spm_id_from=333.999.0.0
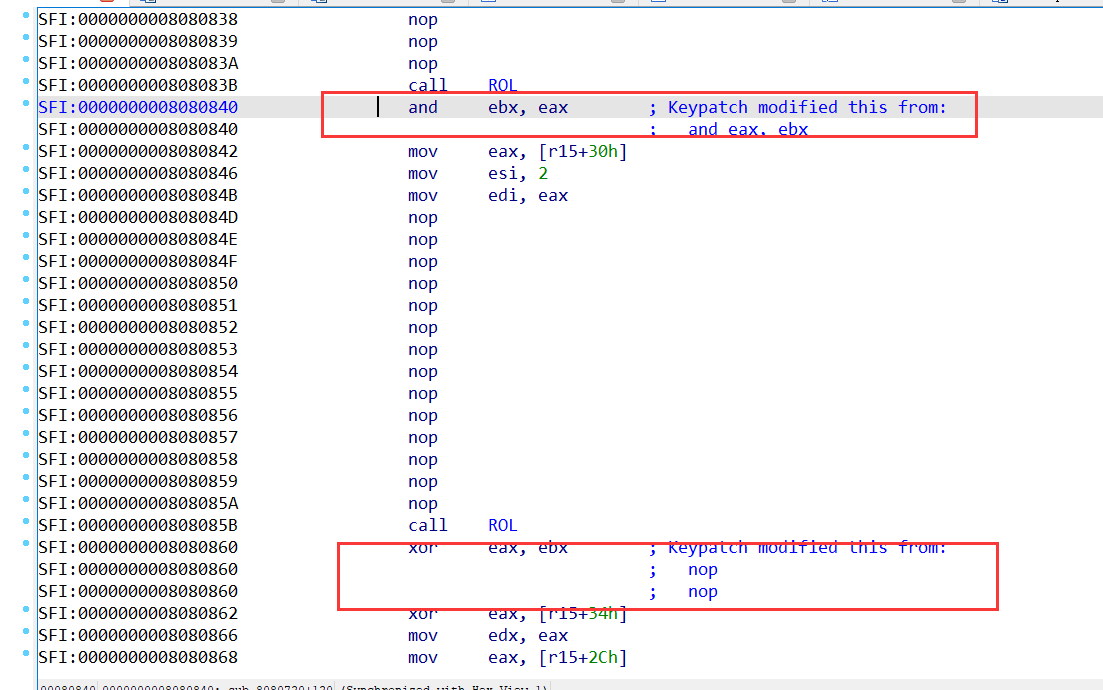
后发现,脚本没有特别完善。这里两个计算指令也nop了,修复回去即可。
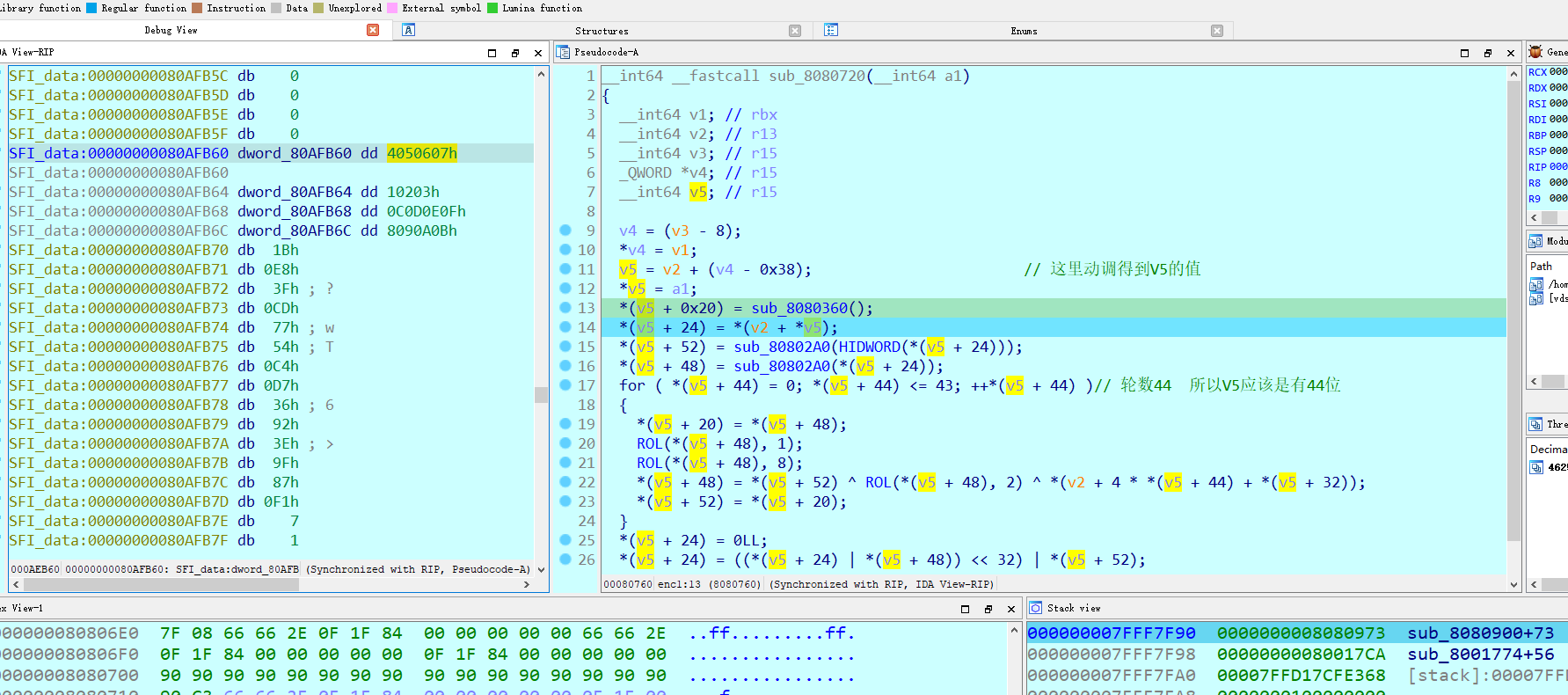
这里观看队内wp,说是Feistel加密,没接触过。这里是动调取得key,然后剩下就是左移异或。
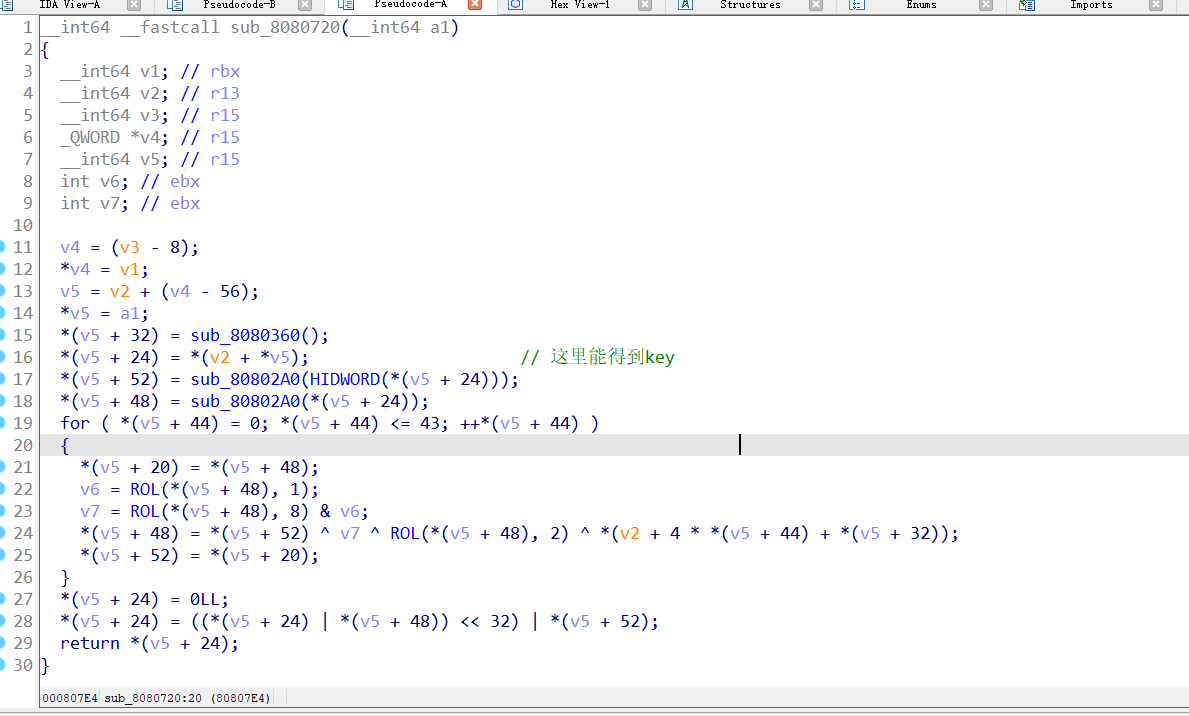
把那两个汇编修复一下就是这样,基本能当源码看
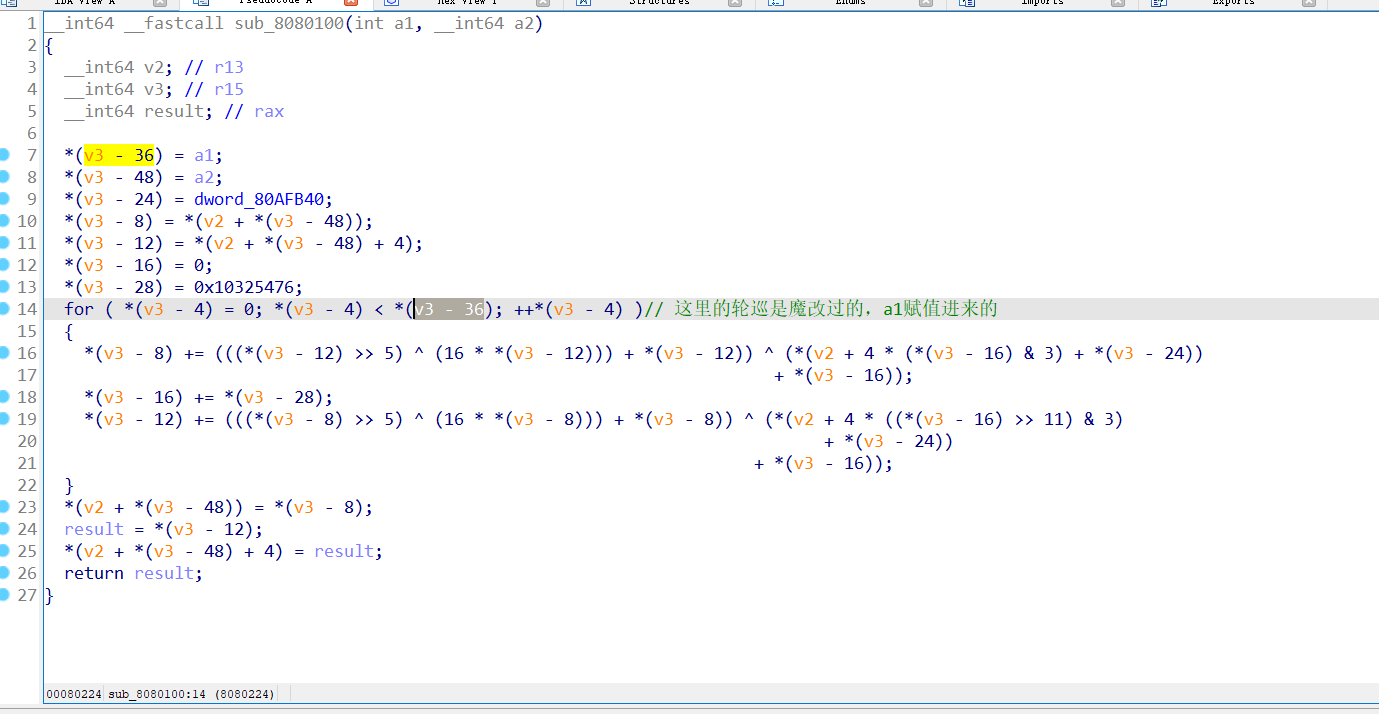
第二个就是xtea,修复过来后就看的非常清晰,key就是v3-24.
from ctypes import *
import binascii
KEY = [0x4050607, 0x10203, 0x0C0D0E0F, 0x8090A0B, 0x0CD3FE81B, 0x0D7C45477,
0x9F3E9236, 0x107F187, 0x0F993CB81, 0x0BF74166C, 0x0DA198427, 0x1A05ABFF,
0x9307E5E4, 0x0CB8B0E45, 0x306DF7F5, 0x0AD300197, 0x0AA86B056, 0x449263BA,
0x3FA4401B, 0x1E41F917, 0x0C6CB1E7D, 0x18EB0D7A, 0x0D4EC4800, 0x0B486F92B,
0x8737F9F3, 0x765E3D25, 0x0DB3D3537, 0x0EE44552B, 0x11D0C94C, 0x9B605BCB,
0x903B98B3, 0x24C2EEA3, 0x896E10A2, 0x2247F0C0, 0x0B84E5CAA, 0x8D2C04F0,
0x3BC7842C, 0x1A50D606, 0x49A1917C, 0x7E1CB50C, 0x0FC27B826, 0x5FDDDFBC,
0x0DE0FC404, 0x0B2B30907]
def ROL(i, index):
return ((i << index) | (i >> (32 - index))) & 0xffffffff
def Feistel(p1, p2):
for i in range(43, -1, -1):
tmp = p2
p2 = (ROL(tmp, 1) & ROL(tmp, 8)) ^ ROL(tmp, 2) ^ KEY[i] ^ p1
p1 = tmp
return p1,p2
def xtea(v, key, r):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x10325476
total = c_uint32(delta * r)
for i in range(r):
v1.value -= (((v0.value << 4) ^ (v0.value >> 5)) + v0.value) ^ (total.value + key[(total.value >> 11) & 3])
total.value -= delta
v0.value -= (((v1.value << 4) ^ (v1.value >> 5)) + v1.value) ^ (total.value + key[total.value & 3])
return v0.value, v1.value
enc = [
0x66, 0xC2, 0xF5, 0xFD, 0x86, 0x82, 0x32, 0x7A, 0x04, 0x40,
0x94, 0xCE, 0xDC, 0x8A, 0xE0, 0x5D, 0x0A, 0xBD, 0xE4, 0xA6,
0xDC, 0xAD, 0xCA, 0x16, 0x0C, 0x6F, 0xCD, 0x13, 0x36, 0xD9,
0x75, 0x1A
]
xtea_key = [
0x03020100, 0x07060504, 0x0B0A0908, 0x0F0E0D0C
]
enc_data = [[0xFDF5C266, 0x7A328286], [0xCE944004, 0x5DE08ADC], [0xA6E4BD0A, 0x16CAADDC], [0x13CD6F0C, 0x1A75D936]]
flag = b''
for i in range(4):
a, b = xtea(enc_data[i], xtea_key, 1 << (1 + i))
c, d = Feistel(b, a)
flag += binascii.a2b_hex(hex(c)[2:])
flag += binascii.a2b_hex(hex(d)[2:])
print(flag)
#mM7pJIobsCTQPO6R0g-L8kFExhYuivBN这里的代码是抄的队内师傅的,这里放上他的博客。
https://www.yuque.com/emtanling
0x3 jump
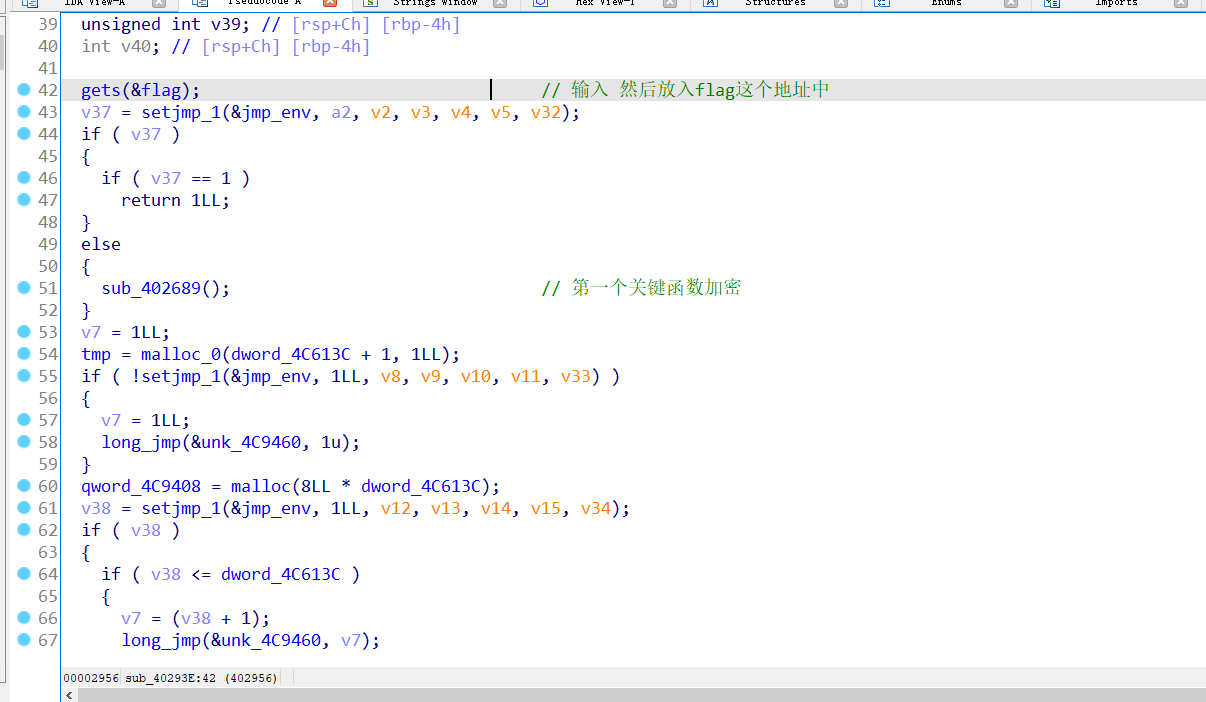
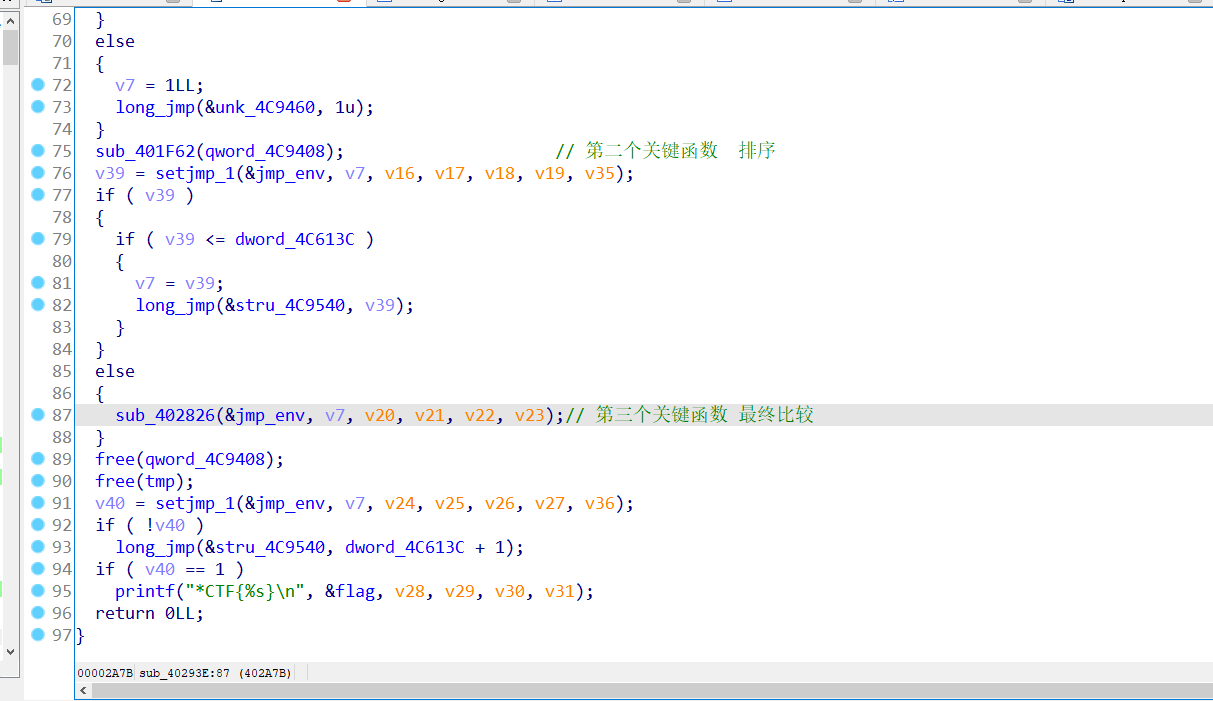
先用 插件figer修复函数,大致分为3个重要函数
第一个函数就是把输入的flag 前面加2 最后面加3 变成一个34位的数组
什么是long_jmp ,什么是set_jmp看下面这篇文章
https://blog.csdn.net/chenyiming_1990/article/details/8683413
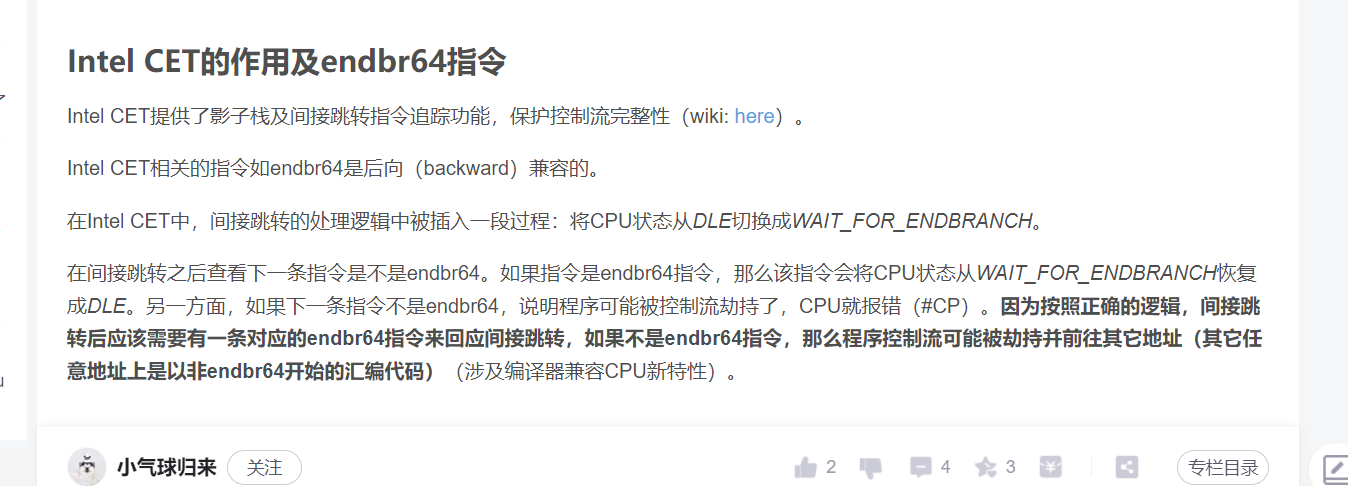
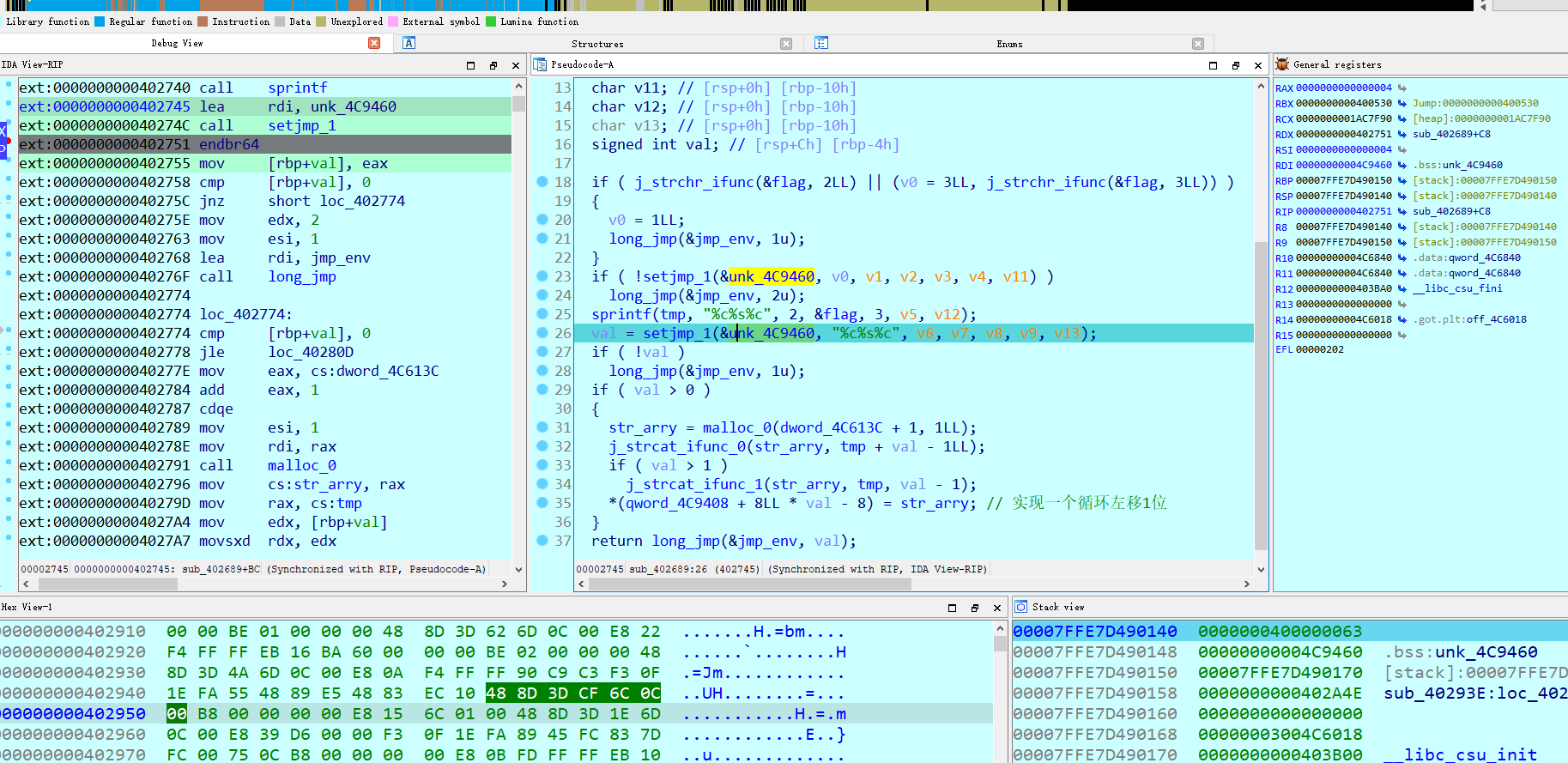
可以看到截图中断到一个这个指令,后面long_jmp调用setjmp 出来的位置就是这个endbr64,图中有解答。间接跳转需要这个endbr64指令来回应
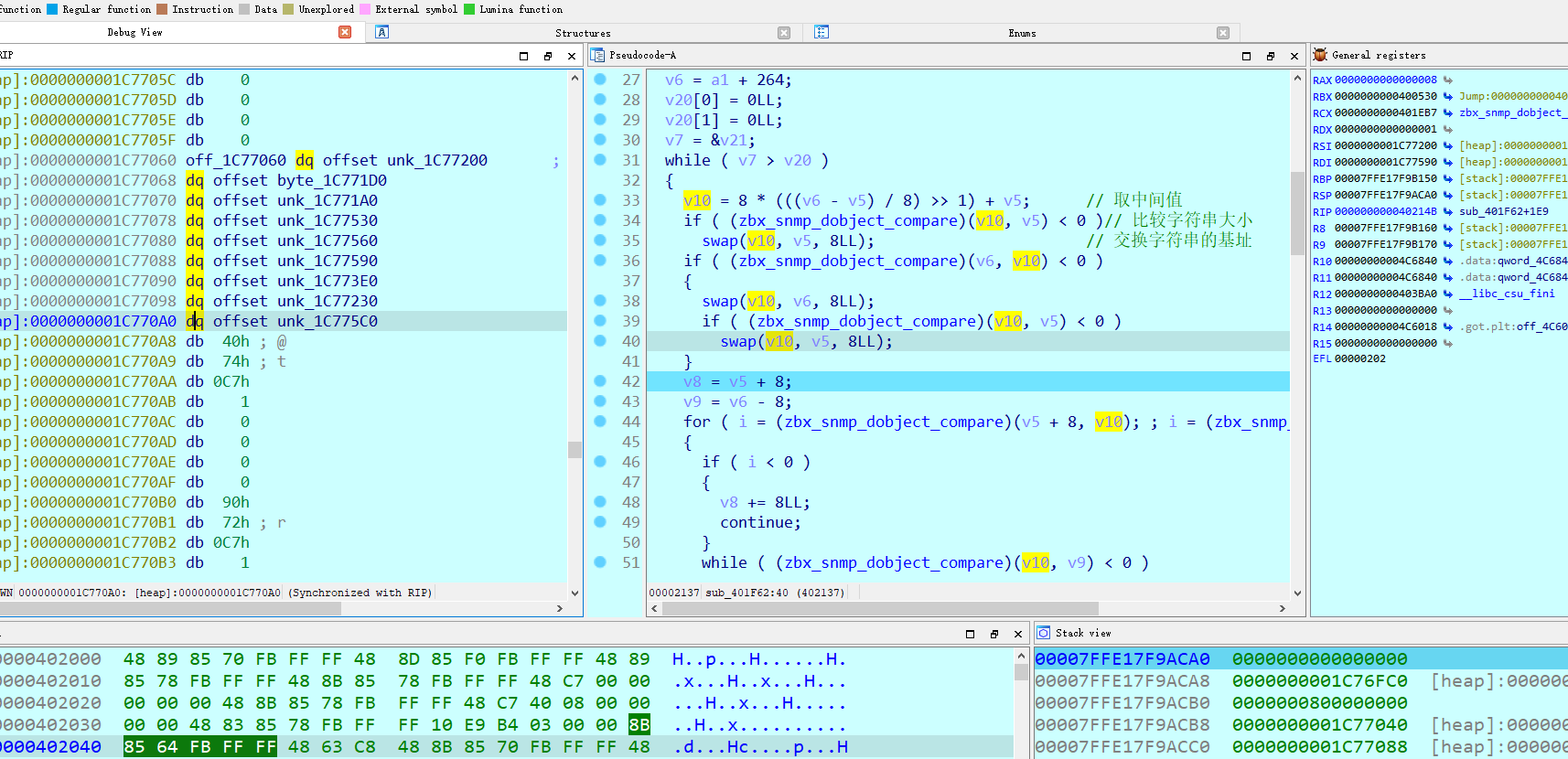
第二个函数 意义就是按照大小来排序每一个flag数组,左边就是存储的每一个数组
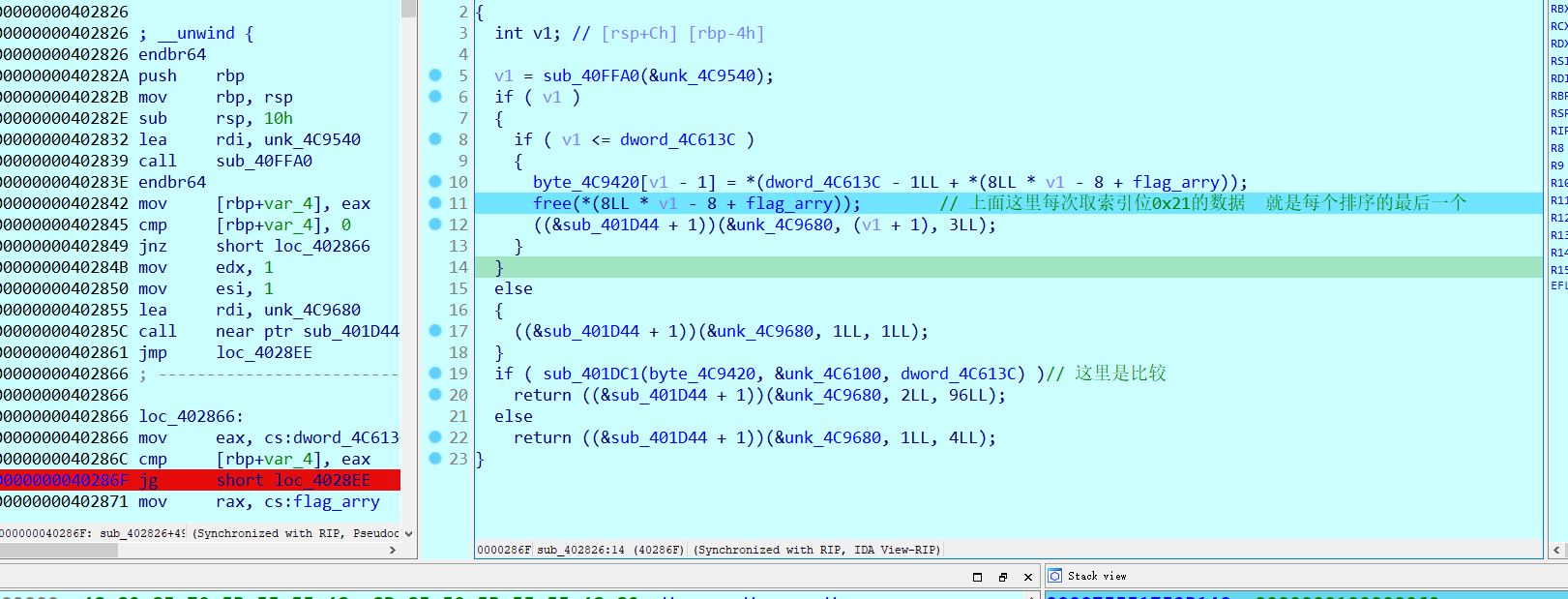
最终就是把每一个数组的最后一位取出来做比较
import copy
enc=[0x03, 0x6A, 0x6D, 0x47, 0x6E, 0x5F, 0x3D, 0x75, 0x61, 0x53, 0x5A, 0x4C, 0x76, 0x4E, 0x34, 0x77, 0x46, 0x78, 0x45, 0x36, 0x52, 0x2B, 0x70, 0x02, 0x44, 0x32, 0x71, 0x56, 0x31, 0x43, 0x42, 0x54, 0x63, 0x6B]
c=copy.deepcopy(enc) #copy.deepcopy函数是一个深复制函数。所谓深复制,就是从输入变量完全复刻一个相同的变量,无论怎么改变新变量,原有变量的值都不会受到影响
c.sort() #排序
flag=[0]*34
flag[0]=2
flag[-1]=3
for i in range(32,-1,-1):
p=c.index(flag[i+1])
flag[i]=enc[p]
print(bytes(flag))
#\x02cwNG1paBu=6Vn2kxSCqm+_4LETvFRZDj\x03最终就是拿出密文,然后排序好,按照索引来取值排序。



